Serverless
Serverless means no server is required to host your code, freeing you from auto-scaling and decoupling overdeads while providing a low-cost model. It is highly suitable for designs that can be broken down into mor modular components. One drawback is cold starts which can affect latency.
Microservices
The clear advantage of microservices is that you have to maintain a smaller code surface area. Microservices should always be independent. You can build each service with no external dependencies where all prerequisites are included. The other overarching concept of microservices is bounded contexts, which are the blocks that combine to make a single business domain. An individual microservice defines boundaries in which all the details are encapsulated.
Best practices for designing microservice architecture:
- Create a separate data store: Adopting a separate data store for each microservice allows the individual team to choose the best database for their service. For example, the website traffic team can use a scalable NoSQL database to store semi-structured data. This also helps to achieve loose coupling where changes in one database do not impact other services.
- Keep servers stateless: Keeping your server stateless helps in scaling. Servers should be able to go down and be replaced easily, with minimal or no need for storing state on the servers.
- Create a separate build: Creating a separate build for each microservice makes it easier for the development team to introduce new changes and improve the agility of the new feature release. This helps to ensure that the development team is only building code required for a particular microservice and not impacting other services.
- Deploy in a container: Deploying in a container gives you the tool to deploy everything in the same standard way. Using containers, you can choose to deploy all microservices in the same way, regardless of their nature.
- Go serverless: Try to use a serverless platform or a leveraging function with service capability, such as AWS Lambda, when your microservices are simple enough. Serverless architecture helps you to avoid infrastructure management overhead.
- Blue-green deployment: For application deployment, the best approach is to create a copy of the production environment. Deploy the new feature and route a small percentage of the user traffic to ensure the new feature is working as expected in a new environment. After that, increase the traffic in the new environment until the entire user base can see the new feature.
- Monitor your environment: Good monitoring is the difference between reacting to an outage and proactively preventing an outage with proper rerouting, scaling, and managed degradation. To prevent application downtime, you want services to offer and push their health status to the monitoring layer
Saga pattern
The Saga pattern is a design pattern used to manage long-running, complex business transactions. It’s beneficial in microservice architectures. The Saga pattern divides the transaction into multiple smaller, isolated transactions. If one of the smaller transactions fails, compensating transactions are executed to undo the previous steps.
In complex systems where multiple services need to work together to fulfill a single operation, such as processing an order or booking a flight, the Saga pattern helps ensure that if something goes wrong at any point, the entire operation can be either fully completed or rolled back.
Here’s how the Saga pattern works:
- Decomposition: The operation that needs to be performed is broken down into smaller, isolated steps or transactions. Each step corresponds to an action performed by a specific microservice.
- Compensation actions: For every step, a corresponding compensation action is defined. If a step fails or an error occurs, the compensation action is executed to reverse the effects of the previous steps. This brings the system back to a consistent state.
- Coordinator: A coordinator is responsible for orchestrating the sequence of steps and their corresponding compensation actions. It initiates the saga, monitors its progress, and ensures that all steps are completed or the necessary compensation actions are taken.
- Local transactions: Each step and its compensation action are encapsulated within a local transaction within their respective microservices. This allows for the atomicity of operations within each microservice.
- Eventual consistency: The Saga pattern embraces eventual consistency, which means that even if a failure occurs, the system will eventually reach a consistent state by either completing the entire operation successfully or rolling back to a consistent state.
Fan-out/fan-in pattern
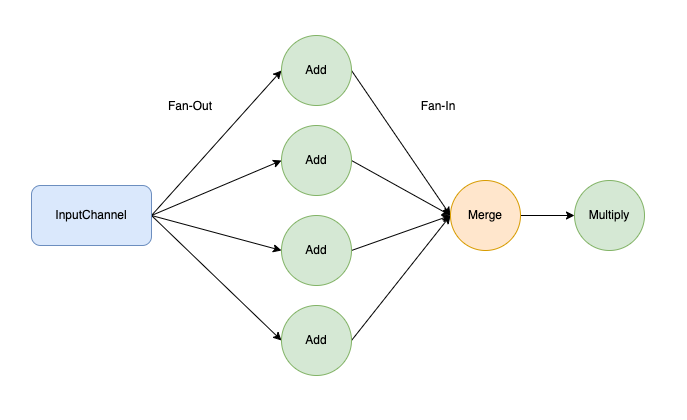
The fan-out/fan-in pattern is a design pattern commonly used in distributed systems to process requests efficiently and aggregate data from multiple sources. It’s beneficial for scenarios where data must be collected, processed, and consolidated from various input streams or sources.
Consider a real-time analytics system for a social media platform. The fan-out/fan-in pattern can be applied to collect and process data from various user activities.
Fan-out phase: In the fan-out phase, data is collected from multiple sources, including different microservices, APIs, or data streams. Each source sends its data to a separate processing component. User posts, comments, likes, shares, and followers generate real-time data streams.The processing component for each source operates independently and simultaneously. This allows for efficient parallel processing, reducing the time to gather data from various sources. Each type of activity has a dedicated processing component that calculates statistics such as engagement rates, popular content, and trending topics
Fan-in phase: Once individual processing is complete, the results from each processing component are aggregated or combined, in this case to calculate overall platform engagement metrics. This aggregation can involve calculations, summarizations, or any other operation needed for the final result. The aggregated data generates the desired outcome or final report. This could be a single report, a summarized analysis, or any other form of consolidated data, For our example, this is presented to administrators as a dashboard that displays real-time engagement insights.
Benefits of the fan-out/fan-in pattern
The fan-out/fan-in pattern is a strategic approach in distributed systems that significantly enhances the way data is managed and processed.
- Parallelism: The pattern leverages parallel processing, allowing faster data collection and aggregation from multiple sources.
- Efficiency: Instead of processing data sequentially from each source, the pattern optimizes processing time by working on multiple sources concurrently.
- Scalability: Each source can be processed independently, enabling the system to scale efficiently as the number of sources increases.
- Modularity: The pattern encourages modular design by separating the data collection (fan- out) phase from the aggregation (fan-in) phase. This makes it easier to maintain and extend the system.
Service Mesh pattern
A service mesh is a layer of the infrastructure that manages communication between different services in a cloud application. It ensures reliable message delivery among these services. Builders can focus on core application programming, while the service mesh takes care of networking and security in the system’s infrastructure.
Here are the primary features provided by a service mesh:
- Traffic management: Service meshes provide detailed control over traffic behavior with rich routing rules, retries, failovers, and fault injection.
- Observability: They give you deep insights into your applications through visualizations, tracing, monitoring, and logging traffic between services.
- Security: Service meshes offer automated mutual TLS (mTLS) traffic encryption between your services. Policy enforcement: They allow you to define and enforce policies consistently across all your services, regardless of where they run.
- Resilience: Service meshes enable advanced load balancing, timeouts, and retries, helping you create more resilient applications. A popular way to implement a service mesh is by using sidecar proxies.
Reactive Architecture
As cloud-native architecture can have various moving parts due to multiple microservices and small modules, they need to be protected from failure. Reactive architecture is a design approach for building software that can efficiently handle changes and stay responsive under various conditions. It benefits large-scale and distributed systems that must maintain high availability and responsiveness, even in the face of failures or high demand. The principles of reactive architecture are based on the Reactive Manifesto, a document that outlines the core traits of reactive systems: responsive, resilient, elastic, and message-driven. You can find details on the Reactive Manifesto by visiting: https://www.reactivemanifesto.org/:
- Responsive: Reactive systems prioritize responsiveness, ensuring they respond to user requests promptly regardless of the system’s load or state.
- Resilient: Reactive systems are designed to handle failures gracefully. They can recover quickly and operate, even when some components fail.
- Elastic: Reactive systems can scale up or down based on demand, efficiently utilizing resources and maintaining responsiveness under varying workloads.
- Message-driven: In reactive systems, components communicate using messages that are passed asynchronously. This approach allows for components to be loosely connected, independently isolated, and accessible from different locations.
To implement the reactive architecture, you can take the following steps:
- Design components to communicate asynchronously using message queues. This prevents blocking and enhances responsiveness.
- Implement the Actor model, where components (actors) communicate through messages. Each actor processes messages sequentially, avoiding concurrency issues.
- Integrate resilience patterns like Circuit Breaker and Bulkhead to handle failures and prevent cascading errors.
- Utilize auto-scaling mechanisms to allocate resources based on load dynamically. Cloud platforms like AWS provide tools for this purpose.
- Leverage reactive libraries or frameworks like Akka, Spring WebFlux, or ReactiveX, which offer abstractions for building reactive systems.
Queuing based architecture
The queue-based architecture provides fully asynchronous communication and a loosely coupled architecture. In a queue-based architecture, your information is still available in the message. If a service crashes, the message can get the process as soon as the service becomes available. Let’s learn some of the terminology of a queue-based architecture:
- Message: A message has two parts-the header and the body. The header contains metadata about the message, while the body contains the actual message.
- Queue: The queue holds the messages that can be used when required.
- Producer: A service that produces and publishes a message to the queue. Consumer: A service that consumes and utilizes the message.
- Message broker: This helps to gather, route, and distribute messages between the producer and consumer.
Queuing chain pattern
A queuing chain pattern is applied when sequential processing needs to run on multiple linked systems. A failure in one part can cause the entire operation to be disrupted. You can use queues between various systems and jobs to remove a single point of failure and design true loosely coupled systems. The queuing chain pattern helps you to link different systems together and increases the number of servers that can process the messages in parallel.
Job observer pattern
In the job observer pattern, you can create an auto-scaling group based on the number of messages in the queue to process. The job observer pattern helps you to maintain performance by increasing or decreasing the number of server instances used in job processing.
Pipes-and-filters
Pipes-and-Filters architecture is a software design pattern that divides complex tasks into a sequence of smaller, independent processing steps or stages. Each stage performs a specific operation on the input data and passes the transformed data to the next stage through a “pipe.” The stages are called “filters,” and the connectors are called “pipes.”
- Filters: These processing units perform specific operations on the data. Filters read input data, process it, and produce output data. Each filter works independently and can be implemented and tested separately.
- Pipes: Pipes are the connectors that transport data between filters. They can be simple data streams or more complex mechanisms, such as message queues, that provide buffering, synchronization, and data format conversion.
The primary advantage of this architectural pattern is that it is a robust structure that promotes separation of concerns and modularity. It is favored for its reusability, composability, sequential processing, and scalability. Individual filters, which perform discrete processing tasks, can be reused across various applications. The composability of these filters allows for easy modification by rearranging the filter. This pattern supports scalability as filters can run in parallel and be distributed across multiple computational nodes.
Event Driven Architecture
Publisher / Subscriber Moel
In the publisher/subscriber (pub/sub) model, when an event is published, a notification is sent to all subscribers, and each subscriber can take the necessary action as per their requirements for data processing.
Event Stream Model
In the event stream model, the consumer can read the continuous flow of events from the producer. For example, you can use the event stream to capture the continuous flow of a clickstream log and also send an alert if there are any anomalies detected.
In EDA, producers and consumers operate independently, with events acting as the communication medium. This decoupling means that producers can send events without knowing which consumers will process them, and consumers can listen for events they are interested in without knowing who produced them. This leads to a flexible and extendable system where new consumers can be added to process events without modifying existing producers, facilitating scalability and adaptability.
Anti-patterns
Avoid the following:
- Single Point of Failure
- Manual Scaling
- Tightly Couped Services
- Ignoring Security Best Practices
- Not Monitoring or Logging
- Ignoring Network Latency
- Lack of Testing
- Not Considering Costs